Ready to talk with GOWIN about your next technology project needs?

The GOWIN Design Services Team have a dedicated team of experts along with a variety of intellectual property (IP) to solve design challenges in with GOWIN traditional and µSoC FPGA products in areas including:
Our knowledgeable and skilled designers are ready to meet customers’ design needs with the most efficient, cost effective, and innovative solutions. GOWIN Design Services Team enables customers to develop more effective and efficient designs. Their experience covers a wide variety of application domain expertise in consumer, communication, industrial, automotive, and medical market segments
GOWIN FPGA Design Services was created to provide access to best-in-class engineering development and support for customized projects using programmable devices. We are here to work with you along the entire design process to ensure your needs to met in a timely fashion. Our project engineers are assigned to projects based on their knowledge, skills, and experience of similar projects or technologies to ensure your project goals are reached.
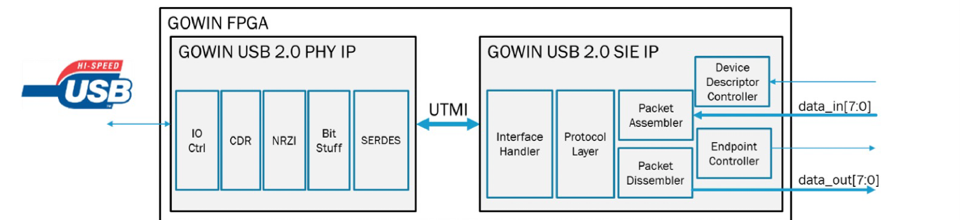
The GW1NRF Bluetooth FPGA is the first uSoC FPGA
to offer a built in Bluetooth transceiver to wirelessly
communicate data.
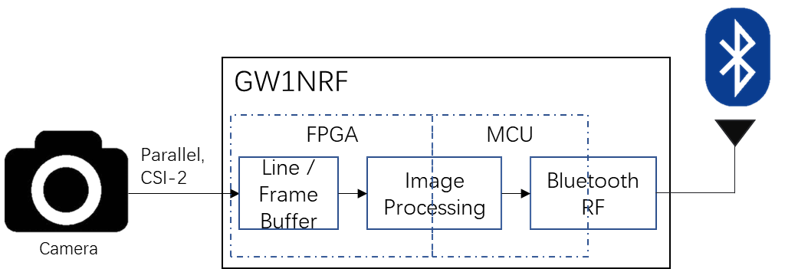
HDMI receiver and transmitter interfaces for resolutions up to 1080p
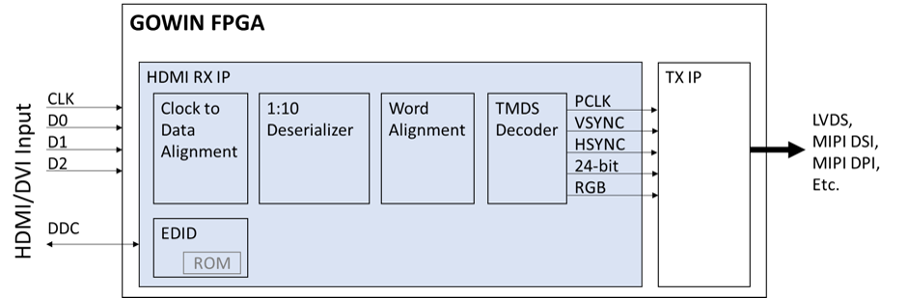
GOWIN’s USB solution is useful for virtually every market segment including consumer, automotive, industrial and communications.